Average opponent win percentage is a fine first cut at strength of schedule (we built it in the SoS explainer). But it has a blind spot: it treats a 10-2 opponent the same whether that opponent earned its record against giants or cupcakes. The fix is to go one level deeper — fold in your opponents' opponents. Here's the two-deep version in Python. Full code: scripts/cfb-two-deep-sos-python.py.
One-deep, then two-deep
One-deep is just the mean of opponents' win percentages. Two-deep blends each opponent's own record with their schedule strength:
one_deep(t) = mean( winpct(o) for o in opponents(t) )
two_deep(t) = mean( 0.67*winpct(o) + 0.33*one_deep(o) for o in opponents(t) )The two-deep term asks: was your opponent's record built against a tough slate (raising its value) or a soft one (lowering it)? It's the same recursive instinct that, taken all the way, becomes an iterative ratings system.
Compute it
Using the shared season helper (ESPN results), build records, then the two passes:
from _cfb_season import season_games, records, winpct, opponents
games = season_games(2024); rec = records(games)
one = {t: mean(winpct(rec, o) for o in opponents(games, t)) for t in teams}
two = {t: mean(0.67*winpct(rec, o) + 0.33*one[o] for o in opponents(games, t)) for t in one}The result
Team 1-deep 2-deep
MICH 64.7% 60.1%
UCLA 64.0% 59.1%
FSU 64.2% 57.6%
VT 60.0% 57.2%
KU 62.9% 56.8%
OSU 57.9% 55.8%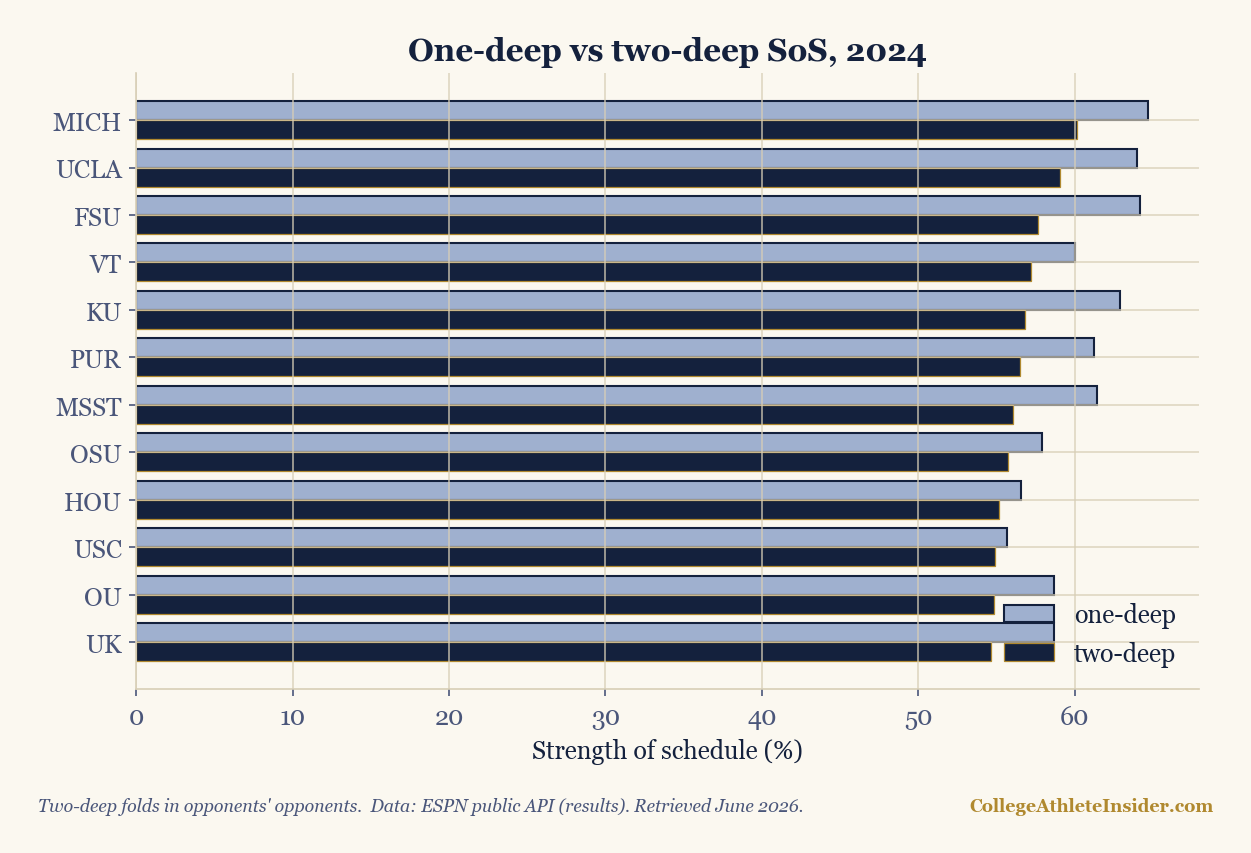
Notice what two-deep does: it compresses the extremes. Michigan's schedule still rates toughest, but its number drops from 64.7% to 60.1% — because some of its opponents' gaudy records were themselves built against softer competition, and the second level discounts that. Two-deep is more conservative and, generally, more accurate. The values cluster tighter because real schedules are more similar than one-deep makes them look.
Where to take it
- Keep going. Three-deep, four-deep… in the limit you've reinvented an iterative rating (our spreadsheet ranking does exactly that). Two-deep captures most of the benefit cheaply.
- Weight by location. A road game against a good team is tougher than the same game at home.
- Drop FCS games or handle them explicitly; they distort win-percentage math.
Sources & further reading
- Free textbook: Chapter 18: Game Outcome Prediction — the theory behind this, at DataField.dev.
- ESPN public API (results) — via
scripts/_cfb_season.py - Companion code:
scripts/cfb-two-deep-sos-python.py - Related: Strength of schedule explained · Adjusted ranking in a spreadsheet